In event sourcing, you can never retire old event versions. APIs let you migrate consumers, deprecate old versions, and eventually remove them. Events don’t work that way. They accumulate indefinitely, and replay means processing every historical event. A CustomerCreated event from 2019 must be processable by code written in 2025.
This post summarises what I’ve learned working with an event-sourced system over the past year. Greg Young has an entire book on this topic, but versioning is still under-discussed in practice.
Producers, consumers, and compatibility direction
In event sourcing, producers (command handlers) write events. Consumers (projections, reactors, aggregates) read them. The compatibility direction depends on which side changes first.
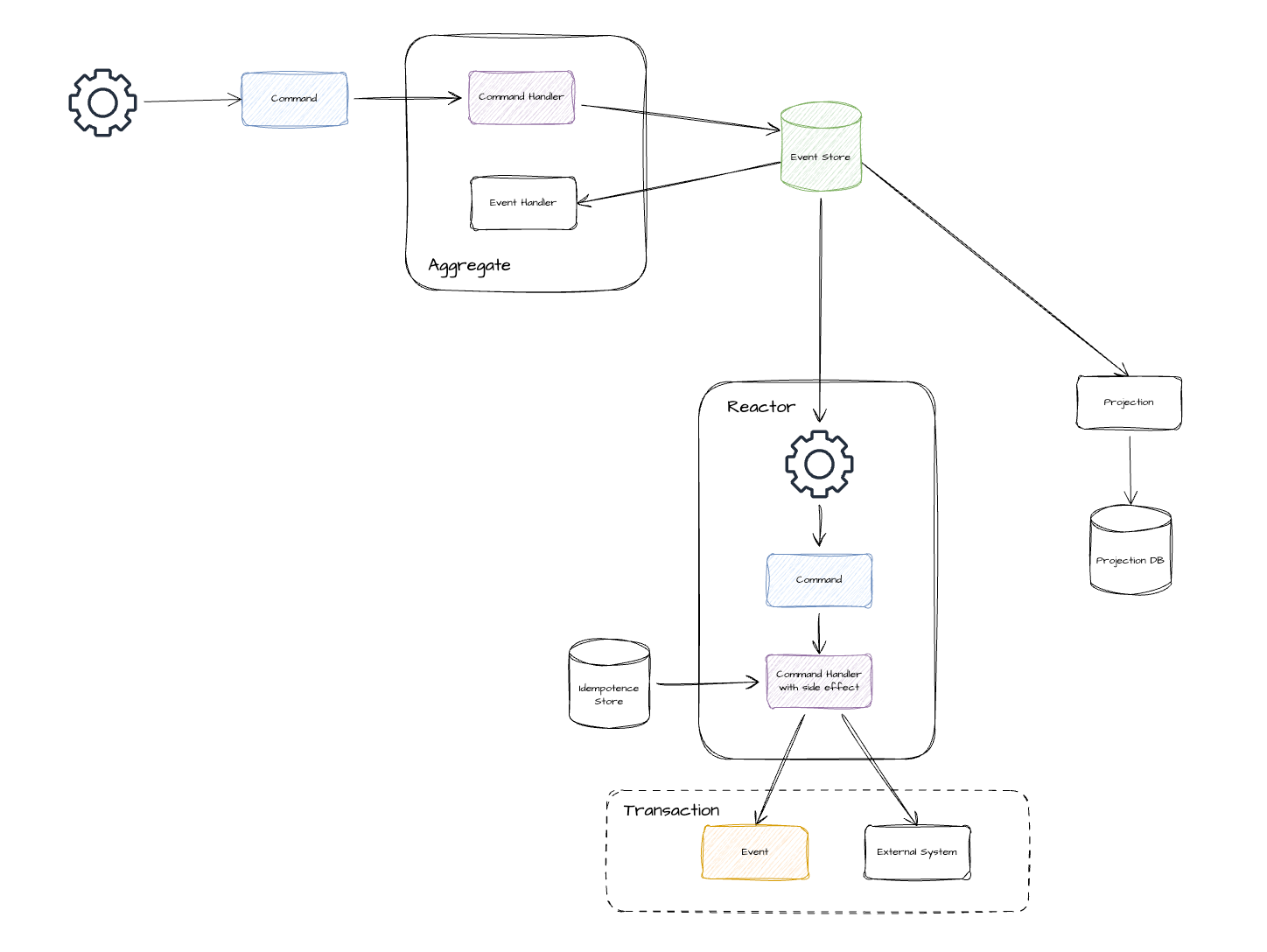
- Consumer changes first (new code reads old events): backward compatibility. This is the replay scenario, and it is always required.
- Producer changes first (old code reads new events): forward compatibility. This is the deployment scenario. During rolling deployments, a new producer may emit events before all consumers have upgraded.
This matters for both internal and external events:
- External/integration events: consumers upgrade on their own schedule. Both backward and forward compatibility are essential.
- Internal/domain events: producers and consumers typically deploy together. Replay still forces new code to process years of old events. During rolling deployments, producers and consumers may temporarily run different versions.
Backward compatibility is mandatory. Forward compatibility is highly desirable: it enables hot-swapping projectors without replay, canary deployments, and zero-downtime upgrades.
Deployment order follows from this. Deploy consumers first. They already need backward compatibility for replay, so no extra work is required. If you deploy producers first, consumers must also be forward compatible.
Choosing a versioning strategy
When a schema change is needed, two questions drive the strategy: is the change backward compatible? And if not, can you convert old events to the new shape?
Backward compatible: evolve the schema in place
Most changes fall here. Add optional fields with sensible defaults. Add new event types for new concepts. Handle missing fields in consumers. No versioning needed.
Adding optional fields with defaults:
type AccountCreated struct {
ID string
CustomerID string
Source string // NEW: defaults to empty string
}Adding new event types:
type AccountSourceUpdated struct { // NEW EVENT
ID string
Source string
}Adding required fields with defaults:
type AccountCreated struct {
ID string
CustomerID string
Status AccountStatus // NEW REQUIRED - default to "Active" when missing
}
func (h *Handler) Handle(event *es.Event) {
var evt AccountCreated
json.Unmarshal(event.Payload, &evt)
if evt.Status == "" {
evt.Status = AccountStatusActive // Default for old events
}
}Handling defaults in projectors and reactors:
func (p *AccountProjector) HandleAccountCreated(event *evt.AccountCreated) {
source := event.Source
if source == "" {
source = "unknown" // Default for old events
}
p.db.Insert(Account{
ID: event.ID,
Source: source,
})
}Reactors follow the same pattern.
Breaking but convertible: new version + upcaster
When the change is not backward compatible, but you can write a pure function that converts the old shape to the new one, create a new event version and use an upcaster. Renaming fields, restructuring payloads, and splitting fields are typical cases.
The litmus test: can you write oldEvent → newEvent without needing external data or context? If yes, upcast.
// Renaming "name" to "firstName" + "lastName"
type CustomerCreatedV1 struct {
ID string
Name string
}
type CustomerCreatedV2 struct {
ID string
FirstName string
LastName string
}
func UpcastCustomerCreated(v1 *CustomerCreatedV1) *CustomerCreatedV2 {
parts := strings.SplitN(v1.Name, " ", 2)
return &CustomerCreatedV2{
ID: v1.ID,
FirstName: parts[0],
LastName: parts[1],
}
}The transformation happens on-the-fly when events are read from the store. No replay needed. Consumers only deal with the latest shape.
Over time, upcaster chains can grow (v1 → v2 → v3). Each upcaster only handles one hop, keeping each one simple. If chains get long, consider a one-time stream migration to compact old versions.
Breaking and not convertible: different event
Sometimes the change is not just structural. The business meaning of the event has changed. When that happens, create a different event entirely.
Examples:
OrderPlacedbecomingOrderSubmittedForApproval(different business process)- A field’s value changing meaning (e.g.,
status: "active"now carries different semantics) - A domain concept splitting into two distinct concepts
An upcaster can’t fix a semantic change because the old data doesn’t carry enough information to derive the new meaning. Old consumers keep working with old events. New consumers handle the new event type.
Last resort: event stream migration
When none of the above work, you can migrate the event stream itself. This typically happens after major schema overhauls or fundamental modelling mistakes. You create a new stream and copy events over, transforming them in the process.
This is the nuclear option. It’s costly, risky, and requires careful coordination. But it’s an escape valve when the event stream has accumulated enough debt that upcasters and new event types can’t dig you out.
Decision matrix
| Change Type | Backward Compatible? | Convertible? | Strategy |
|---|---|---|---|
| Add optional field with default | Yes | N/A | Evolve schema in place |
| Add new event type | Yes | N/A | Evolve schema in place |
| Remove optional field | Yes | N/A | Deprecate first, remove after grace period |
| Add required field | With defaults | N/A | Evolve schema in place (default in consumer) |
| Rename field | No | Yes | Upcast to new version |
| Restructure payload | No | Yes | Upcast to new version |
| Change field type | No | Usually | Upcast if convertible, otherwise new event |
| Change semantics | No | No | Create different event |
Testing compatibility
Test that your projectors and reactors can handle both old and new event schemas:
func TestAccountProjector_BackwardCompatibility(t *testing.T) {
t.Run("handles old events without Source field", func(t *testing.T) {
oldEvent := `{"ID":"123","CustomerID":"456"}` // No Source
var evt evt.AccountCreated
json.Unmarshal([]byte(oldEvent), &evt)
projector.HandleAccountCreated(&evt)
account := projector.db.Get("123")
require.Equal(t, "unknown", account.Source) // Default applied
})
t.Run("handles new events with Source field", func(t *testing.T) {
newEvent := `{"ID":"123","CustomerID":"456","Source":"web"}`
var evt evt.AccountCreated
json.Unmarshal([]byte(newEvent), &evt)
projector.HandleAccountCreated(&evt)
account := projector.db.Get("123")
require.Equal(t, "web", account.Source)
})
}Beyond schema: versioning value object behavior
The strategies above deal with the shape of event data. Validation logic embedded in value objects is another source of breaking changes.
I encountered this when a Phone value object’s validation changed. It initially accepted any 8-digit number, but we later tightened it to only accept Australian country codes (61).
// Old validation - accepts any 8-digit number
func NewPhone(phone string) (*Phone, error) {
if len(phone) != 8 {
return nil, fmt.Errorf("invalid phone")
}
return &Phone{value: phone}, nil
}
// New validation - only accepts Australia (+61) country code
func NewPhone(phone string) (*Phone, error) {
if !strings.HasPrefix(phone, "61") || len(phone) != 8 {
return nil, fmt.Errorf("invalid phone")
}
return &Phone{value: phone}, nil
}During replay, projections failed when loading historical CustomerCreated events because older events contained non-Australian country codes that were valid at the time. The deserialization succeeded, but validation rejected historically valid data.
This reveals a deeper issue: validation logic is a form of schema that evolves over time.
Strategy 1: Plain data structures for events (Recommended)
Separate event data from domain behavior. Use plain data types in events, applying validation only when reconstructing domain objects:
// Event payload - plain data structure
type CustomerCreatedEvent struct {
Phone string // Plain string, no validation
}
// Domain model uses value object
type Customer struct {
phone *Phone
}
func NewCustomer(event CustomerCreatedEvent) (*Customer, error) {
phone, err := NewPhone(event.Phone) // Validated at construction
if err != nil {
return nil, err
}
return &Customer{phone: phone}, nil
}Tradeoffs: you lose compile-time safety in the event layer. Current validation might also reject historical data during domain reconstruction, which you must handle gracefully.
Strategy 2: Lazy validation
Delay validation until domain operations, skipping validation during deserialization from events:
func NewPhoneWithSkip(phone string, skipValidation bool) (*Phone, error) {
if !skipValidation && !strings.HasPrefix(phone, "61") {
return nil, fmt.Errorf("invalid phone")
}
return &Phone{value: phone}, nil
}
// Use for loading from event store
phone, _ := NewPhoneWithSkip(eventData.Phone, true)Tradeoffs: flexible and preserves domain guarantees for new operations, but requires discipline to use the correct constructor in different contexts (event loading vs. new operations). Easy to misuse.
Strategy 3: Version value objects
Version value objects alongside events. When validation logic changes, create new versions of affected value objects and events.
Tradeoffs: most type-safe approach, but leads to version explosion as every value object change cascades to all events using it. Rarely practical in production systems.
Role of schema registry
The strategies so far focus on what individual teams can do in code. For organisations with distributed event ownership, a schema registry adds guardrails at the infrastructure level. It provides two key benefits:
-
Validation and compatibility enforcement: automatically validates that producers conform to registered schemas and enforces compatibility rules. This prevents breaking changes from reaching production and enables safe rolling upgrades.
-
Centralized schema management: provides a single source of truth for event schemas across independent teams, enabling schema discovery, impact analysis, and governance without direct coordination.
When to consider a schema registry
- Independence of teams: producers and consumers are managed by different teams, especially across time zones or organizations.
- Rate of evolution: frequent schema changes benefit from automated compatibility checks.
- Reliability requirements: preventing invalid events from reaching production is essential.
- External events: integration events are exposed to external consumers who upgrade independently.
For internal/domain events in a monorepo where producers and consumers share code, the overhead of a schema registry may outweigh its benefits. The decision matrix and testing patterns above provide sufficient guardrails for most teams.
Key principles
- Events are contracts. Treat event schemas as public APIs that must be stable.
- Backward compatibility is mandatory. New code must always handle old events.
- Deploy consumers first. They already need backward compatibility for replay.
- Test with old events. Include historical event shapes in tests to catch regressions.
- Prefer expansion over modification. Add new events rather than changing existing ones.
- Version as a last resort. Use explicit versions only when breaking changes are unavoidable.
- Apply Postel’s Law. Producers should emit strict, well-formed events. Consumers should tolerate missing fields and unexpected values.